
Published on 4 minutes
Postgresql Versus Greenplum
→ Server configuration
- a dataset of 30M/60M and 100M rows
- 16GO RAM
- 500GO SSD
- 8 core
→ Postgresql
version 13.1
madlib 1.17
configured with pgtune
max_connections = 20 shared_buffers = 4GB effective_cache_size = 12GB maintenance_work_mem = 2GB checkpoint_completion_target = 0.9 wal_buffers = 16MB default_statistics_target = 500 random_page_cost = 1.1 effective_io_concurrency = 200 work_mem = 26214kB min_wal_size = 4GB max_wal_size = 16GB max_worker_processes = 8 max_parallel_workers_per_gather = 4 max_parallel_workers = 8 max_parallel_maintenance_workers = 4
→ Greenplum
- version 6.12
- madlib 1.17
- 4 segments
- default configurations
→ Overall results
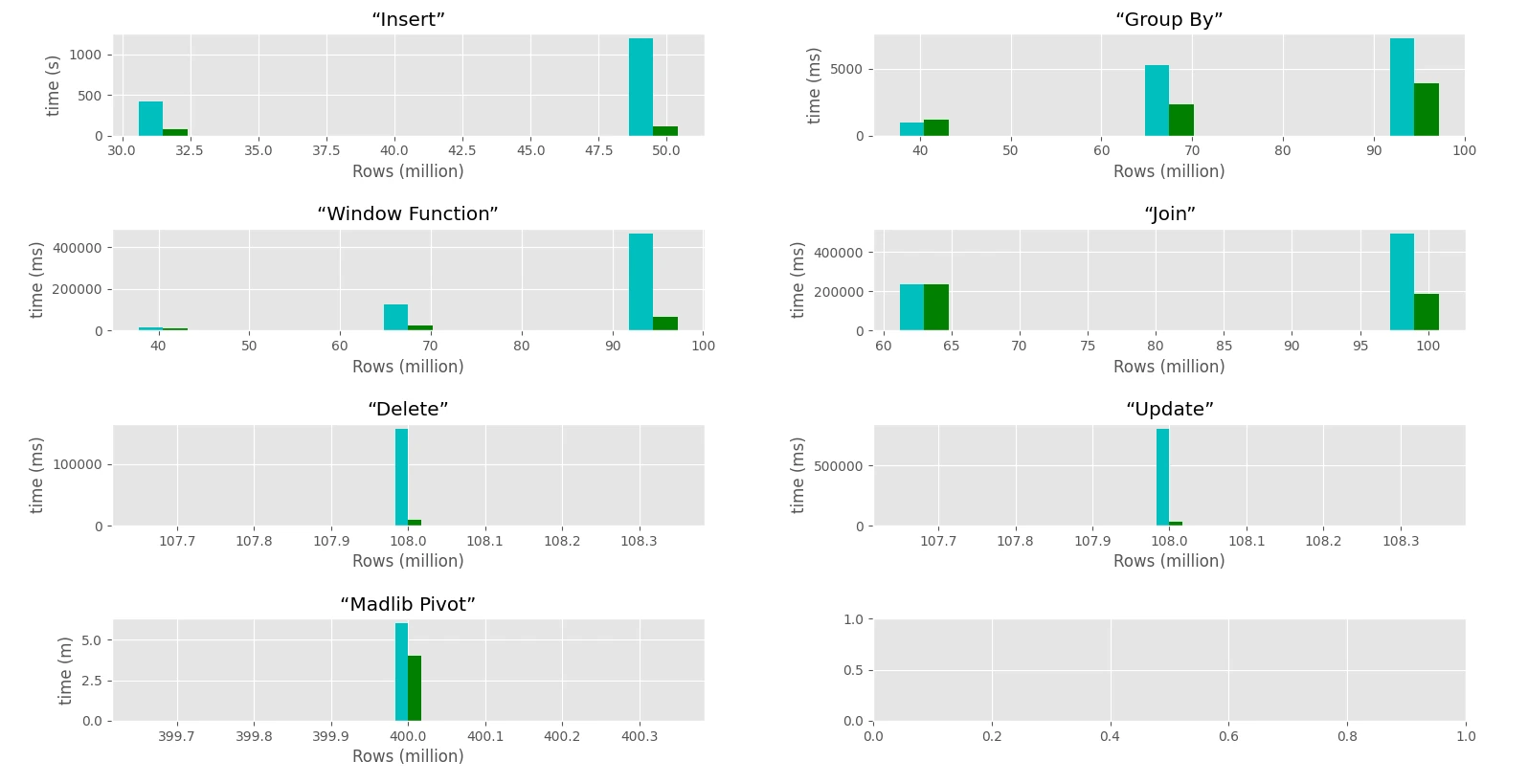
→ conclusion
From this preliminary results, Greeplum is superior to postgreSQL on a standalone server, which is very surprining because it is supposed to work on a distrinbuted cluster.
Greenplum is way faster than postgres in the context of datawarhousing and managing large tables in every domains: insert/update/delete/select. It provides a set of tools such gptext, madlib, map-reduce, pl/python-R and PFX which looks relevant. Also it provides 'queues' to makes multi-users collaborate better.
While postgreSQL is effective on a 30M rows table, it struggles to handle larger tables.
→ SQL
→ Postgresql
create table labevents(
row_id integer
, subject_id integer
, hadm_id integer
, itemid integer
, charttime timestamp(0) without time zone
, value character varying(200)
, valuenum double precision
, valueuom character varying(20)
, flag character varying(20)
, mimic_id integer
) ;
CREATE TABLE
warehouse=# \copy labevents from 'labevents.csv' csv ;
COPY 27854055
Time: 353750.640 ms (05:53.751)
warehouse=# select count(*) c, c1.flag from labevents as c1 group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
18009889 |
9779594 | abnormal
64572 | delta
(3 rows)
Time: 939.223 ms
warehouse=# select c1.row_id, row_number() over(partition by c1.itemid order by c1.row_id desc) rk from labevents as c1 limit 10;
row_id | rk
----------+----
27906665 | 1
27906621 | 2
27906612 | 3
27906561 | 4
27906550 | 5
27906507 | 6
27906370 | 7
27906325 | 8
27906270 | 9
27906257 | 10
(10 rows)
Time: 13714.732 ms (00:13.715)
warehouse=# insert into labevents select * from labevents;
INSERT 0 27854055
Time: 423631.155 ms (07:03.631)
warehouse=# select count(*) c, c1.flag from labevents as c1 group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
36019778 |
19559188 | abnormal
129144 | delta
(3 rows)
Time: 5295.608 ms (00:05.296)
warehouse=# select c1.row_id, row_number() over(partition by c1.itemid order by c1.row_id desc) rk from labevents as c1 limit 10;
row_id | rk
----------+----
27906665 | 1
27906665 | 2
27906621 | 3
27906621 | 4
27906612 | 5
27906612 | 6
27906561 | 7
27906561 | 8
27906550 | 9
27906550 | 10
(10 rows)
Time: 126347.700 ms (02:06.348)
warehouse=# select count(*) c, c1.flag from labevents as c1 join labevents c2 on c1.row_id = c2.row_id group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
72039556 |
39118376 | abnormal
258288 | delta
(3 rows)
Time: 234570.663 ms (03:54.571)
warehouse=# insert into labevents select * from labevents;
INSERT 0 55708110
Time: 1201961.089 ms (20:01.961)
warehouse=# select count(*) c, c1.flag from labevents as c1 group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
72039556 |
39118376 | abnormal
258288 | delta
(3 rows)
Time: 7277.858 ms (00:07.278)
warehouse=# select c1.row_id, row_number() over(partition by c1.itemid order by c1.row_id desc) rk from labevents as c1 limit 10;
row_id | rk
----------+----
27906665 | 1
27906665 | 2
27906665 | 3
27906665 | 4
27906621 | 5
27906621 | 6
27906621 | 7
27906621 | 8
27906612 | 9
27906612 | 10
(10 rows)
Time: 465615.775 ms (07:45.616)
warehouse=# select count(*) c, c1.flag from labevents as c1 join labevents c2 on c1.row_id = c2.row_id group by c1.flag order by c desc limit 10 ;
c | flag
-----------+----------
288158224 |
156473504 | abnormal
1033152 | delta
(3 rows)
Time: 494615.953 ms (08:14.616)
warehouse=# delete from labevents where row_id < 5000000;
DELETE 19952316
Time: 157689.975 ms (02:37.690)
warehouse=# update labevents set flag = 'new flag' where row_id < 10000000;
UPDATE 19949040
Time: 810058.857 ms (13:30.059)
create unlogged table tbl_range (data1 text, data2 text, randomnumber double precision);
insert into tbl_range
( select
('{a,b,c,d,e,f}'::text[])[1 + floor(random() * 6)] as data1
,('{g,h,i,j,k,l}'::text[])[1 + floor(random() * 6)] as data2
,random() * 1000 as randomnumber
from generate_series(1,400000000));
SELECT madlib.pivot('tbl_range', 'pivout', 'data1', 'data2', 'randomnumber', 'sum,max');
→ Greenplum
warehouse=# create table labevents(
row_id integer
,subject_id integer
,hadm_id integer
,itemid integer
,charttime timestamp(0) without time zone
,value character varying(200)
,valuenum double precision
,valueuom character varying(20)
,flag character varying(20)
,mimic_id integer
) with (appendonly=true, orientation=column, compresstype=ZSTD );
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'row_id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
warehouse=# \copy labevents from '/home/nparis/labevents.csv' csv ;
COPY 27854055
Time: 80878,637 ms
warehouse=# select count(*) c, c1.flag from labevents as c1 group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
18009889 |
9779594 | abnormal
64572 | delta
(3 rows)
Time: 1164,303 ms
warehouse=# select c1.row_id, row_number() over(partition by c1.itemid order by c1.row_id desc) rk from labevents as c1 limit 10;
row_id | rk
----------+----
27907576 | 1
27907382 | 2
27901097 | 3
27901054 | 4
27900783 | 5
27897288 | 6
27896669 | 7
27894567 | 8
27892281 | 9
27884982 | 10
(10 rows)
Time: 12569,391 ms
warehouse=# insert into labevents select * from labevents;
INSERT 0 27854055
Time: 79361,173 ms
warehouse=# select count(*) c, c1.flag from labevents as c1 group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
36019778 |
19559188 | abnormal
129144 | delta
(3 rows)
Time: 2353,157 ms
warehouse=# select c1.row_id, row_number() over(partition by c1.itemid order by c1.row_id desc) rk from labevents as c1 limit 10;
row_id | rk
----------+----
27906665 | 1
27906665 | 2
27906621 | 3
27906621 | 4
27906612 | 5
27906612 | 6
27906561 | 7
27906561 | 8
27906550 | 9
27906550 | 10
(10 rows)
Time: 25409,642 ms
warehouse=# select count(*) c, c1.flag from labevents as c1 join labevents c2 on c1.row_id = c2.row_id group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
72039556 |
39118376 | abnormal
258288 | delta
(3 rows)
Time: 101654,716 ms
warehouse=# insert into labevents select * from labevents;
INSERT 0 55708110
Time: 112203,521 ms
warehouse=# select count(*) c, c1.flag from labevents as c1 group by c1.flag order by c desc limit 10 ;
c | flag
----------+----------
72039556 |
39118376 | abnormal
258288 | delta
(3 rows)
Time: 3941,551 ms
warehouse=# select c1.row_id, row_number() over(partition by c1.itemid order by c1.row_id desc) rk from labevents as c1 limit 10;
row_id | rk
----------+----
27906665 | 1
27906665 | 2
27906665 | 3
27906665 | 4
27906621 | 5
27906621 | 6
27906621 | 7
27906621 | 8
27906612 | 9
27906612 | 10
(10 rows)
Time: 65279,232 ms
warehouse=# select count(*) c, c1.flag from labevents as c1 join labevents c2 on c1.row_id = c2.row_id group by c1.flag order by c desc limit 10 ;
c | flag
-----------+----------
288158224 |
156473504 | abnormal
1033152 | delta
(3 rows)
Time: 188816,067 ms
warehouse=# delete from labevents where row_id < 5000000;
DELETE 19952316
Time: 8930,371 ms
warehouse=# update labevents set flag = 'new flag' where row_id < 10000000;
UPDATE 19949040
Time: 32977,965 ms
nparis@gnubuntu:~/bin$ /opt/greenplum-db-6-6.12.1/bin/gpload -f gpload.yaml
2020-12-04 18:16:38|INFO|gpload session started 2020-12-04 18:16:38
2020-12-04 18:16:38|INFO|started gpfdist -p 8081 -P 8082 -f "/home/nparis/labevents.csv" -t 30
2020-12-04 18:17:49|INFO|running time: 71.18 seconds
2020-12-04 18:17:49|INFO|rows Inserted = 27854055
2020-12-04 18:17:49|INFO|rows Updated = 0
2020-12-04 18:17:49|INFO|data formatting errors = 0
2020-12-04 18:17:49|INFO|gpload succeeded
warehouse=# create table tbl_range (data1 text, data2 text, randomnumber double precision) with (appendonly=true, orientation=column, compresstype=ZLIB );
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'data1' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
Time: 352,343 ms
warehouse=# insert into tbl_range
( select
('{a,b,c,d,e,f}'::text[])[1 + floor(random() * 6)] as data1
,('{g,h,i,j,k,l}'::text[])[1 + floor(random() * 6)] as data2
,random() * 1000 as randomnumber
from generate_series(1,100000000)) ;
INSERT 0 100000000
Time: 145408,190 ms
warehouse=# SELECT madlib.pivot('tbl_range', 'pivout', 'data1', 'data2', 'randomnumber', 'sum,max');
pivot
-------
(1 row)
Time: 67074,359 ms
create table tbl_range (data1 text, data2 text, randomnumber double precision) with (appendonly=true, orientation=column, compresstype=ZLIB );
insert into tbl_range
( select
('{a,b,c,d,e,f}'::text[])[1 + floor(random() * 6)] as data1
,('{g,h,i,j,k,l}'::text[])[1 + floor(random() * 6)] as data2
,random() * 1000 as randomnumber
from generate_series(1,400000000));
SELECT madlib.pivot('tbl_range', 'pivout', 'data1', 'data2', 'randomnumber', 'sum,max');
This page was last modified:

